Neues Lexikon für eine alte Sprache
17.01.2023Altarmenische Verben stehen im Zentrum eines neuen Forschungsprojekts am Lehrstuhl für Vergleichende Sprachwissenschaft der Universität Würzburg. Ziel ist ein korpusbasiertes Valenzlexikon, das digital zur Verfügung steht.
Altarmenisch ist die älteste erhaltene Varietät der armenischen Sprache. Seine Quellen reichen an den Anfang des 5. Jahrhunderts zurück, als die älteste erhaltene Bibelübersetzung in dieser Sprache verfasst wurde. Seine Grammatik stellt eine komplexe Verschmelzung indogermanischer Urformen und zahlreicher Innovationen dar, die sich sowohl aus internen Veränderungen als auch aus dem Kontakt mit Nachbarsprachen Ostanatoliens und des Südkaukasus ergaben. Trotz seines Wertes für die allgemeine, typologische und historische Linguistik ist das altarmenische Korpus bislang nur unzureichend technisch aufbereitet worden.
Das soll sich in den kommenden Jahren ändern: 2023 startet am Lehrstuhl für Vergleichende Sprachwissenschaft der Julius-Maximilians-Universität Würzburg (JMU) ein neues Forschungsprojekt, das von der Deutschen Forschungsgemeinschaft (DFG) für den Zeitraum von drei Jahren finanziert wird: das „Altarmenische Valenzlexikon“ – oder CAVAL: Classical Armenian Valency Lexicon.
Verantwortlich dafür ist der Sprachwissenschaftler Dr. Petr Kocharov, der bereits seit März 2021 als Stipendiat der Alexander von Humboldt-Stiftung Gast am Lehrstuhl von Professor Daniel Kölligan ist. Auch in diesem Projekt hat sich Kocharov mit dem klassischen Armenisch beschäftigt.
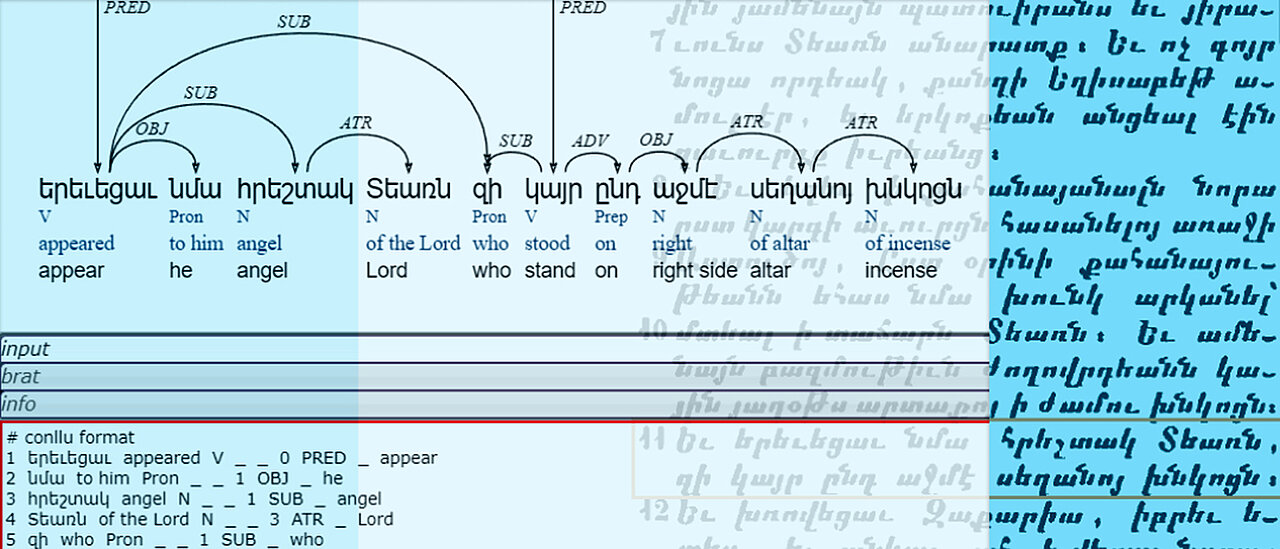
Ein Valenzlexikon, das automatisch generiert wird
„Es gibt zwar auch heute schon diverse Sammlungen digitalisierter altarmenischer Texte. Allerdings ist nur ein relativ kleiner Teil dieser Texte mit morphologischen Annotationen versehen, syntaktisch annotierte Texte sind die Ausnahme“, beschreibt Daniel Kölligan den Hintergrund des Projekts. Auf der Grundlage der vorhandenen Ressourcen wollen die Sprachwissenschaftler deshalb jetzt ein Korpus morphologisch und syntaktisch annotierter Texte erstellen. Dieses soll anschließend die Basis für ein umfassendes Valenzlexikon bilden, das automatisch generiert wird.
Valenz: Darunter versteht die Sprachwissenschaft die sogenannte „Wertigkeit“ eines Verbs – also dessen Eigenschaft, durch weitere Satzglieder ergänzt werden zu können. Beispielsweise besitzt das Verb „regnen“ in der Aussage „Es regnet“ die Wertigkeit Null, während „helfen“ in dem Satz „Stefan hilft seinem Vater“ zweiwertig ist. Im Deutschen kann die Valenz Werte zwischen null und vier annehmen.
Verknüpfung zu weiteren Valenzlexika
„Das Lexikon wird mit einer flexiblen Benutzerschnittstelle ausgestattet sein, die Suchabfragen nach Argumentstrukturen, ihrer morphologischen Ausprägung, der lexikalischen Verteilung und deren Frequenz ermöglichen wird“, sagt Petr Kocharov. Zusätzlich wird es an eine Reihe digitaler Valenzlexika anknüpfen, die in den vergangenen Jahren für andere altindogermanische Sprachen erstellt wurden, insbesondere für Latein und das homerische Griechisch.
Um die Forschung im Bereich der vergleichenden historischen Syntax zu erleichtern, wird CAVAL eine etymologische Annotation einführen, welche die Verknüpfung von CAVAL mit Valenzlexika anderer altindogermanischer Sprachen ermöglichen und damit einen neuen Typus diachroner Valenzlexika indogermanischer Sprachen initiieren wird.
„Bislang gibt es keine digitalen Valenzlexika für Varietäten des Armenischen“, sagt Petr Kocharov. CAVAL sei somit ein Modellprojekt, das auch auf nachklassische Varietäten des Armenischen angewendet werden kann, einschließlich der beiden modernen Literatursprachen, Ost- und Westarmenisch, und der modernen Dialekte.
Kontakt
Dr. Petr Kocharov, Lehrstuhl für Vergleichende Sprachwissenschaft, T: +49 931 31-82550, petr.kocharov@uni-wuerzburg.de