LAREX
The open source tool LAREX (Layout Analysis and Region Extraction) was originally developed for the semi-automatic, rule-based segmentation of historical documents, in particular the various versions and different variants of the Narrenschiff catalogued in the Narragonien digital project. The main focus was on the fine-grained classification of regions (image, body text, heading, marginalia, ...), which can be flexibly customised using an easily comprehensible rule system. Thanks to continuous further development, LAREX can now also be used as a comprehensive correction tool that enables the labelling and improvement of all (intermediate) results of the segmentation and text recognition steps of an OCR workflow. This includes region and line polygons, their reading order and semantic typing as well as the textual content.
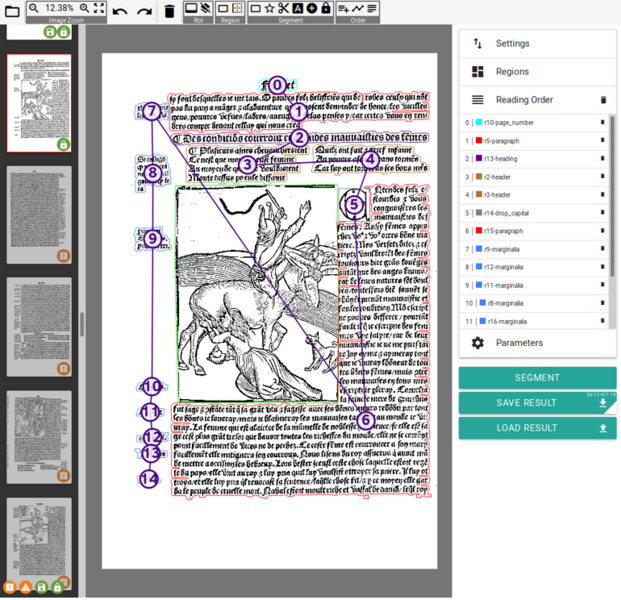
Figure 1: Compressed view of the LAREX correction GUI with the page selection on the left, the selected page and its current markup status in the centre, additional information and settings on the right and the toolbar at the top.
LAREX is now an integral part of OCR4all, but can also be operated as a stand-alone web application. To track further development and for suggestions for improvement, please refer to GitHub. Instructions for use can be found in the OCR4all manual here.
Related Publications
Reul, C., Springmann, U., and Puppe, F.: LAREX - A semi-automatic open-source Tool for Layout Analysis and Region Extraction on Early Printed Books. In: Proceedings of the 2nd International Conference on Digital Access to Textual Cultural Heritage (2017). URL